











Concevoir un logiciel capable de résister aux défaillances est une responsabilité fondamentale pour toute équipe d’ingénierie. La résilience n’est pas simplement une fonctionnalité ; elle constitue le pilier des systèmes distribués modernes. Pour y parvenir, nous devons aller au-delà de l’architecture statique et examiner les interactions dynamiques entre les composants. Les diagrammes de séquence offrent un outil puissant pour cette analyse. En cartographiant le flux des messages et des données, nous pouvons repérer les points faibles avant qu’ils ne se transforment en incidents en production. Ce guide explore comment utiliser l’analyse des diagrammes de séquence pour construire des systèmes robustes et tolérants aux pannes.
1. Les fondements des diagrammes de séquence dans l’architecture 🧩
Avant de plonger dans la résilience, nous devons comprendre l’outil lui-même. Un diagramme de séquence est une représentation visuelle des interactions entre objets ou composants au fil du temps. Il montre l’ordre des messages, les acteurs impliqués et le déroulement temporel des événements. Dans le contexte de la conception de systèmes résilients, ces diagrammes servent de plan directeur pour le comportement sous contrainte.
Lors de l’analyse d’un système, nous ne cherchons pas seulement les parcours idéaux. Nous explorons les limites. Le parcours idéal est la situation où tout fonctionne parfaitement. Le parcours difficile est celui où surviennent une latence réseau, des crashs de services ou une corruption des données. Les diagrammes de séquence nous permettent de visualiser ces deux parcours simultanément. Cette dualité est essentielle pour une conception systématique du système.
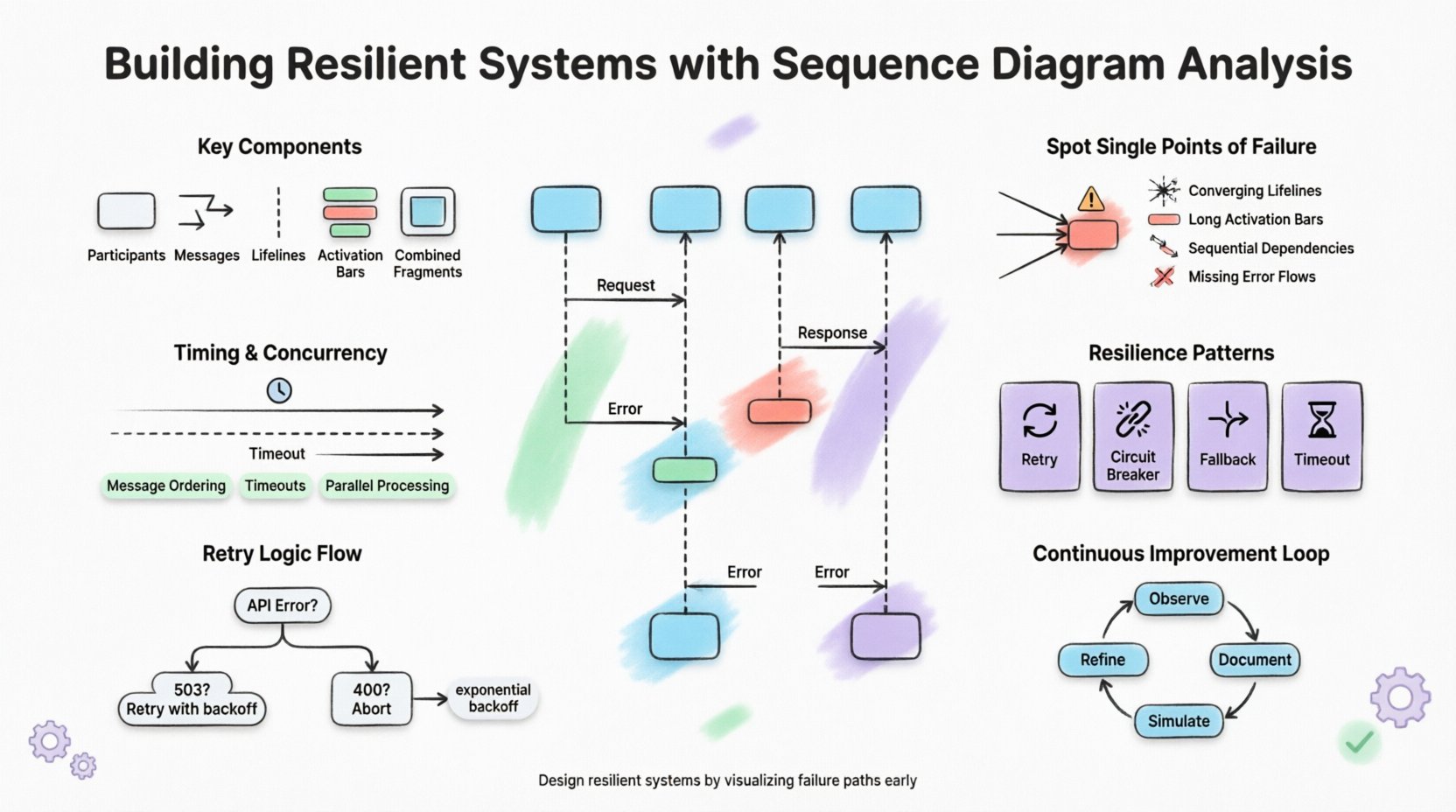
Composants clés à modéliser
- Participants : Représentent les services, bases de données ou API externes impliqués dans le processus.
- Messages : Montrent le flux des requêtes et des réponses entre les participants.
- Lignes de vie : Indiquent l’existence d’un objet sur une période donnée.
- Barres d’activation : Montrent quand un objet effectue une action.
- Fragments combinés : Permettent de représenter les boucles, les alternatives et les sections facultatives.
En définissant rigoureusement ces éléments, nous établissons un contrat de comportement. Ce contrat devient la base des tests et de la validation. Si l’implémentation ne correspond pas au diagramme de séquence, alors il existe un écart dans la conception. Cet écart est souvent là où les défaillances prennent leur source.
2. Identifier les points de défaillance uniques 🔍
L’un des objectifs principaux de l’analyse des diagrammes de séquence est de dévoiler les points de défaillance uniques. Un point de défaillance unique est un composant dont la défaillance entraîne l’effondrement de l’ensemble du système. Dans un diagramme de séquence, ces points apparaissent souvent comme un chemin critique où chaque message doit passer par un nœud spécifique.
Prenons un exemple typique de traitement des commandes. Si chaque commande doit passer par un service de validation spécifique avant d’atteindre la passerelle de paiement, ce service de validation devient un goulot d’étranglement. Si celui-ci tombe en panne, toute la chaîne de traitement des commandes s’arrête. Les diagrammes de séquence rendent cette dépendance visible immédiatement.
Indicateurs visuels de risque
| Élément visuel | Implication pour la résilience | Exemple |
|---|---|---|
| Lignes de vie convergentes | Plusieurs flux dépendent d’un même composant | Commande, Paiement et Notification passent tous par un même service d’authentification |
| Barres d’activation longues | Le composant est occupé pendant de longues périodes | Appel bloquant lors d’une requête synchrone |
| Dépendances séquentielles | Une erreur à l’étape A bloque l’étape B | L’étape 1 doit être terminée avant que l’étape 2 ne commence |
| Flux d’erreur manquants | Aucune gestion des scénarios d’échec | Seuls les messages de retour de succès sont affichés |
Pour atténuer ces risques, nous devons redessiner la séquence. Cela pourrait impliquer l’introduction de redondance ou le changement du flux pour qu’il soit asynchrone. L’objectif est de garantir qu’une défaillance d’un composant ne se propage pas jusqu’à un arrêt total du système.
3. Analyse de la concurrence et des contraintes de temporisation ⏱️
La résilience concerne aussi le temps. Les systèmes échouent souvent non pas à cause d’erreurs logiques, mais à cause de problèmes de temporisation. Les conditions de course, les délais d’attente et les scénarios de blocage sont difficiles à détecter dans le code, mais clairs sur les diagrammes de séquence. Lorsque plusieurs composants agissent simultanément, l’ordre des opérations importe.
Par exemple, imaginez un utilisateur qui met à jour son profil tout en demandant simultanément une session de connexion. Si le diagramme de séquence ne tient pas compte du moment de ces requêtes concurrentes, le système pourrait traiter une version obsolète des données. Cela entraîne une incohérence des données, une source fréquente de problèmes de résilience.
Techniques d’analyse du temps
- Ordre des messages :Assurez-vous que les messages dépendants sont envoyés dans le bon ordre.
- Durées d’attente :Précisez combien de temps un composant attend une réponse avant d’abandonner.
- Traitement parallèle :Utilisez des fragments combinés pour montrer des opérations indépendantes qui s’exécutent en même temps.
- Synchronisation d’état :Vérifiez que les mises à jour d’état ont lieu avant que les actions dépendantes ne se produisent.
En annotant le diagramme avec des contraintes de temps, nous obligeons l’équipe à prendre en compte la latence. Cela est crucial pour les systèmes qui dépendent de données en temps réel. Si un service attend une réponse dans les 500 millisecondes, le diagramme de séquence doit refléter cette attente. Si le service en aval ne peut pas répondre dans ce délai, le diagramme met en évidence un mode potentiel d’échec.
4. Intégration directe des modèles de résilience 🔄
Les modèles de résilience sont des solutions éprouvées aux problèmes architecturaux courants. Parmi eux, on trouve les disjoncteurs, les cloisons étanches et la logique de réessai. Plutôt que d’ajouter ces modèles en dernier recours, nous pouvons les intégrer directement dans le diagramme de séquence. Cela garantit que l’équipe de conception comprend comment ces modèles interagissent avec le reste du système.
Modèles courants dans le flux
- Mécanismes de réessai :Montrez une boucle où un message est renvoyé après un échec.
- Délais d’attente :Indiquez une ligne pointillée verticale là où le message cesse d’attendre.
- Alternatives :Montrez un chemin alternatif pris lorsque le service principal échoue.
- Disjoncteurs : Représente un état où le système cesse d’envoyer des requêtes à un service défaillant.
Lors de la modélisation de ces motifs, la clarté est essentielle. Nous devrions utiliser des notations distinctes pour les échecs et la récupération. Par exemple, une flèche cassée peut indiquer un message échoué. Une flèche pointillée peut indiquer une nouvelle tentative. Ce langage visuel permet aux parties prenantes de comprendre rapidement la stratégie de gestion des erreurs.
| Motif | Représentation par diagramme | Avantage |
|---|---|---|
| Nouvelle tentative | Fragment de boucle avec condition | Empêche les échecs temporaires de provoquer des erreurs |
| Disjoncteur | Message conditionnel (état ouvert) | Empêche les défaillances en chaîne vers les services en aval |
| Réserve | Fragment alternatif (Alt) | Fournit une expérience dégradée mais fonctionnelle |
| Délai d’attente | Fragment combiné avec limite de temps | Empêche les ressources d’être maintenues indéfiniment |
En visualisant ces motifs, nous passons de la théorie abstraite à une conception concrète. Les développeurs peuvent voir exactement où la logique de nouvelle tentative s’applique et ce qui déclenche la réserve. Cela réduit l’ambiguïté pendant l’implémentation.
5. Gérer efficacement les délais d’attente et les nouvelles tentatives ⏳
Les réseaux sont instables. Les services tombent en panne. La latence augmente brusquement. Un système résilient doit gérer ces réalités avec élégance. Les diagrammes de séquence sont le meilleur endroit pour définir les règles relatives aux délais d’attente et aux nouvelles tentatives. Sans ces définitions, les développeurs font des hypothèses qui varient d’une personne à l’autre.
Prenons en compte une intégration avec une API externe. Si l’API renvoie une erreur 503 Service Unavailable, le système doit-il tenter immédiatement une nouvelle tentative ? Doit-il attendre ? Combien de fois ? Ces questions doivent être résolues dès la phase de conception. Le diagramme de séquence fournit le canevas pour ces décisions.
Définition de la logique de nouvelle tentative
- Retard exponentiel : Le temps d’attente augmente à chaque tentative de nouvelle tentative.
- Nombre maximum de tentatives : Une limite stricte sur le nombre de fois où une requête peut être réessayée.
- Classification des erreurs : Distinction entre les erreurs temporaires (réessayables) et les erreurs permanentes (ne pas réessayer).
- Files de lettres mortes : Déplacement des messages échoués vers un stockage distinct pour analyse.
Lors de la documentation de cela dans un diagramme, nous devrions préciser les conditions pour chaque branche. Par exemple, « Si la réponse est 500, réessayer jusqu’à 3 fois avec un délai exponentiel. Si la réponse est 400, abandonner ». Ce niveau de détail garantit que le code correspond à l’intention du design.
Il est également important de tenir compte de l’impact des réessais sur le système. Un nombre excessif de réessais peut submerger le service même en difficulté. Ce phénomène est connu sous le nom de problème de la meute tonnante. Les diagrammes de séquence aident à visualiser cette charge. En montrant plusieurs requêtes concurrentes qui tentent de se répéter, nous pouvons observer le risque d’épuisement des ressources.
6. Communication entre systèmes et frontières 🌐
Les systèmes modernes sont distribués. Ils s’étendent sur plusieurs environnements, clouds ou centres de données. La communication entre ces frontières introduit de la complexité. Les partitions réseau, les pannes du DNS et les règles de pare-feu peuvent toutes perturber le flux. Les diagrammes de séquence aident à cartographier clairement ces frontières.
Lors de la réalisation d’un diagramme de séquence pour un système distribué, nous devrions séparer visuellement différents domaines. Cela peut être fait en utilisant des cadres partitionnés ou des couleurs de fond distinctes. Cette séparation met en évidence les endroits où se trouvent les frontières de confiance et où l’encryption est nécessaire.
Sécurité et résilience
- Flux d’authentification : Assurez-vous que les jetons sont transmis de manière sécurisée entre les services.
- Chiffrement : Indiquez où les données sont chiffrées en transit.
- Limitation de débit : Montrez où les requêtes sont limitées pour prévenir les abus.
- Validation des entrées : Confirmez que les données sont vérifiées avant traitement.
En incluant ces éléments de sécurité dans le diagramme de séquence, nous nous assurons que la résilience ne concerne pas seulement la disponibilité, mais aussi l’intégrité et la confidentialité. Un système disponible mais compromis n’est pas résilient.
7. Collaboration et normes de documentation 🤝
Un diagramme de séquence est un outil de communication. Il comble l’écart entre les architectes, les développeurs et les testeurs. Pour être efficace, il doit suivre des normes cohérentes. Cela garantit que tout le monde interprète le diagramme de la même manière.
Meilleures pratiques pour la maintenance
- Contrôle de version :Traitez les diagrammes comme du code. Stockez-les dans des systèmes de contrôle de version.
- Processus de revue :Incluez les diagrammes dans les réunions de revue de code et de conception.
- Documents vivants : Mettez à jour les diagrammes lorsque le système change. Les diagrammes obsolètes sont dangereux.
- Validation automatisée : Utilisez des outils pour vérifier que l’implémentation correspond au diagramme.
Quand un diagramme devient obsolète, il perd sa valeur. Il peut induire les développeurs en erreur en leur faisant croire qu’une fonctionnalité fonctionne alors qu’elle ne fonctionne pas. Pour éviter cela, nous devons intégrer les mises à jour des diagrammes dans le pipeline de déploiement. Si le code change, le diagramme doit changer. Cela crée une culture d’exactitude et de fiabilité.
8. Affinement itératif et maintenance 🔄
La conception du système n’est jamais terminée. Au fur et à mesure que nous apprenons davantage sur le comportement du système, nous affinons les diagrammes. Ce processus itératif est essentiel pour la résilience à long terme. Nous ne pouvons pas prédire chaque mode de défaillance, mais nous pouvons améliorer notre compréhension au fil du temps.
Après un incident en production, nous devrions examiner les diagrammes de séquence. Le diagramme reflétait-il ce qui s’est réellement produit ? Si non, pourquoi ? Cette analyse post-mortem nous aide à améliorer nos compétences en modélisation. Elle nous aide à identifier les lacunes dans notre compréhension du système.
Boucle d’amélioration continue
- Observer :Surveiller le comportement du système en production.
- Documenter :Mettre à jour les diagrammes pour refléter le comportement observé.
- Simuler :Utiliser l’ingénierie du chaos pour tester les scénarios du diagramme.
- Affiner :Ajuster la conception en fonction des résultats de la simulation.
En traitant le diagramme de séquence comme un artefact vivant, nous nous assurons qu’il reste une représentation fidèle du système. Cela nous permet de détecter les problèmes tôt. Cela nous permet de prévoir les défaillances. Et en fin de compte, cela nous permet de construire des systèmes durables.
Réflexions finales sur la conception des systèmes 🏁
Construire des systèmes résilients exige de la discipline. Cela nous oblige à penser à l’échec avant qu’il ne se produise. L’analyse des diagrammes de séquence fournit la structure dont nous avons besoin pour cela. Elle nous oblige à examiner les détails. Elle nous oblige à considérer les limites.
En utilisant efficacement ces diagrammes, nous pouvons réduire les risques. Nous pouvons améliorer la fiabilité. Nous pouvons créer un logiciel dont les utilisateurs peuvent avoir confiance. Ce n’est pas une question de magie ou de raccourcis. Il s’agit d’une analyse rigoureuse et d’une communication claire. Quand nous avons la séquence juste, le système suit.

