











Diseñar software que resista los fallos es una responsabilidad crítica para cualquier equipo de ingeniería. La resiliencia no es solo una característica; es la columna vertebral de los sistemas distribuidos modernos. Para lograr esto, debemos mirar más allá de la arquitectura estática y examinar las interacciones dinámicas entre los componentes. Los diagramas de secuencia proporcionan una herramienta poderosa para este análisis. Al trazar el flujo de mensajes y datos, podemos identificar puntos débiles antes de que se conviertan en incidentes en producción. Esta guía explora cómo utilizar el análisis de diagramas de secuencia para construir sistemas robustos y tolerantes a fallos.
1. La base de los diagramas de secuencia en la arquitectura 🧩
Antes de adentrarnos en la resiliencia, debemos comprender la herramienta en sí. Un diagrama de secuencia es una representación visual de las interacciones entre objetos o componentes a lo largo del tiempo. Muestra el orden de los mensajes, los actores involucrados y la cronología de los eventos. En el contexto del diseño de sistemas resilientes, estos diagramas sirven como una plantilla para el comportamiento bajo estrés.
Al analizar un sistema, no solo buscamos los caminos felices. Buscamos los límites. El camino feliz es el escenario en el que todo funciona perfectamente. El camino desafortunado es aquel en el que ocurre latencia de red, los servicios fallan o los datos se corrompen. Los diagramas de secuencia nos permiten visualizar ambos caminos simultáneamente. Esta dualidad es esencial para un diseño de sistema completo.
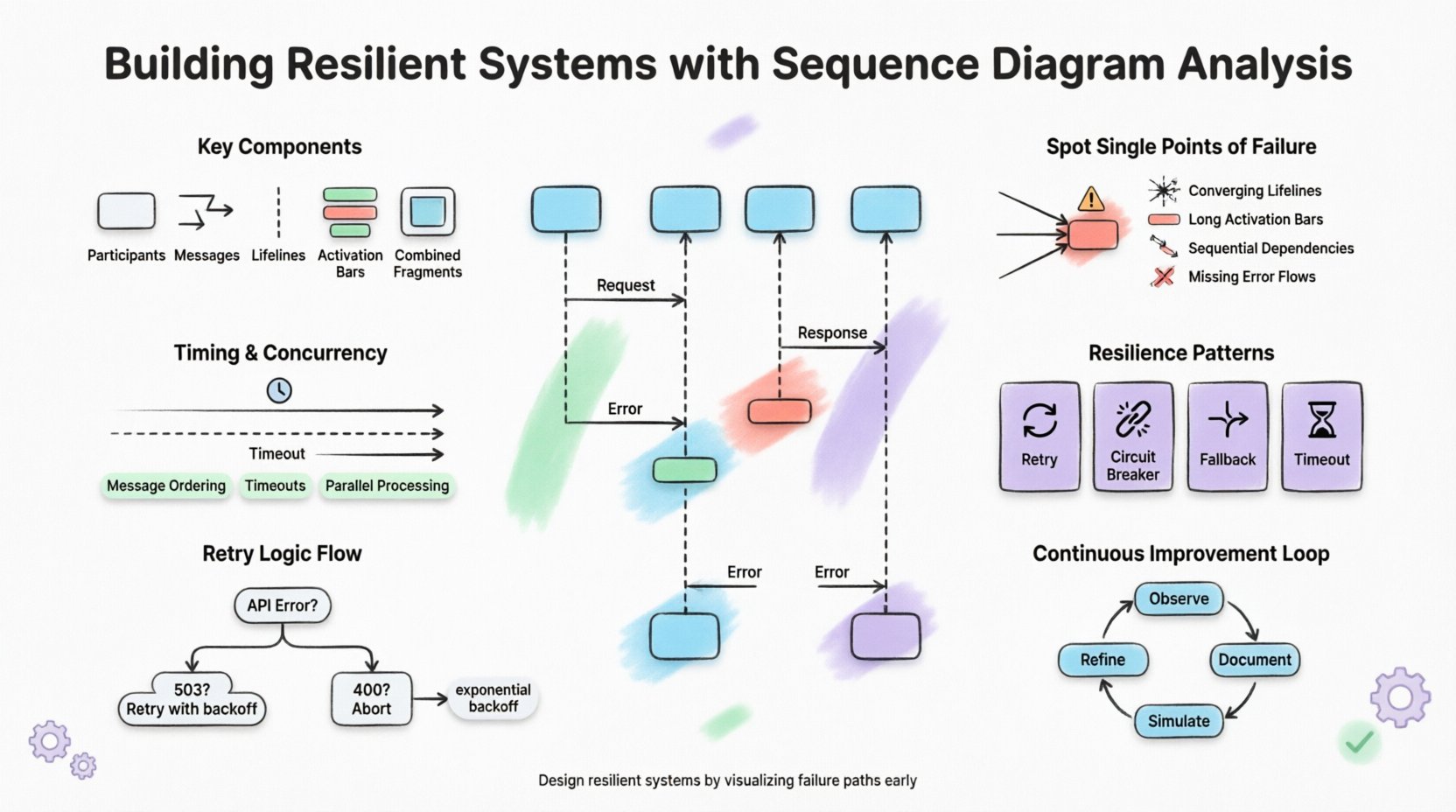
Componentes clave para modelar
- Participantes: Representan los servicios, bases de datos o APIs externas involucrados en el proceso.
- Mensajes: Muestran el flujo de solicitudes y respuestas entre los participantes.
- Líneas de vida: Indican la existencia de un objeto durante un período de tiempo.
- Barras de activación: Muestran cuándo un objeto está realizando una acción.
- Fragmentos combinados: Permiten representar bucles, alternativas y secciones opcionales.
Al definir rigurosamente estos elementos, creamos un contrato de comportamiento. Este contrato se convierte en la base para la prueba y la validación. Si la implementación no coincide con el diagrama de secuencia, hay una brecha en el diseño. Esta brecha es a menudo donde surgen los fallos.
2. Identificación de puntos únicos de fallo 🔍
Uno de los objetivos principales del análisis de diagramas de secuencia es descubrir puntos únicos de fallo. Un punto único de fallo es un componente cuyo fallo provoca el colapso de todo el sistema. En un diagrama de secuencia, estos a menudo aparecen como una ruta crítica donde todos los mensajes deben pasar por un nodo específico.
Considere un flujo típico de procesamiento de pedidos. Si cada pedido debe pasar por un servicio específico de validación antes de llegar a la pasarela de pagos, ese servicio de validación se convierte en un cuello de botella. Si se cae, toda la cadena de pedidos se detiene. Los diagramas de secuencia hacen visible esta dependencia de inmediato.
Indicadores visuales de riesgo
| Elemento visual | Implicación para la resiliencia | Ejemplo |
|---|---|---|
| Líneas de vida convergentes | Varios flujos dependen de un solo componente | Orden, Pago y Notificación todos acceden a un único servicio de autenticación |
| Barras de activación largas | El componente está ocupado durante períodos prolongados | Llamada bloqueante durante una solicitud síncrona |
| Dependencias secuenciales | Un fallo en el paso A bloquea el paso B | El paso 1 debe completarse antes de que comience el paso 2 |
| Flujos de error ausentes | Sin manejo para escenarios de fallo | Solo se muestran los mensajes de retorno de éxito |
Para mitigar estos riesgos, debemos rediseñar la secuencia. Esto podría implicar introducir redundancia o cambiar el flujo para que sea asíncrono. El objetivo es garantizar que el fallo de un componente no se propague hasta causar una falla total del sistema.
3. Análisis de concurrencia y restricciones de tiempo ⏱️
La resiliencia también tiene que ver con el tiempo. Los sistemas a menudo fallan no por errores lógicos, sino por problemas de tiempo. Las condiciones de carrera, los tiempos de espera y los escenarios de bloqueo son difíciles de detectar en el código, pero son evidentes en los diagramas de secuencia. Cuando múltiples componentes actúan simultáneamente, el orden de las operaciones importa.
Por ejemplo, imagina a un usuario que actualiza su perfil al mismo tiempo que solicita una sesión de inicio de sesión. Si el diagrama de secuencia no tiene en cuenta el momento de estas solicitudes concurrentes, el sistema podría procesar una versión desactualizada de los datos. Esto conduce a inconsistencias en los datos, una causa común de problemas de resiliencia.
Técnicas de análisis de tiempo
- Orden de mensajes:Asegúrese de que los mensajes dependientes se envíen en el orden correcto.
- Duraciones de tiempo de espera:Especifique cuánto tiempo un componente espera una respuesta antes de abortar.
- Procesamiento paralelo:Utilice fragmentos combinados para mostrar operaciones independientes que se ejecutan al mismo tiempo.
- Sincronización de estado:Verifique que las actualizaciones de estado ocurran antes de que se produzcan las acciones dependientes.
Al anotar el diagrama con restricciones de tiempo, obligamos al equipo a considerar la latencia. Esto es crucial para sistemas que dependen de datos en tiempo real. Si un servicio espera una respuesta dentro de 500 milisegundos, el diagrama de secuencia debe reflejar esa expectativa. Si el servicio de bajo nivel no puede cumplir con esto, el diagrama destaca un posible modo de fallo.
4. Incorporación directa de patrones de resiliencia 🔄
Los patrones de resiliencia son soluciones probadas para problemas arquitectónicos comunes. Ejemplos incluyen interruptores de circuito, compartimentos estancos y lógica de reintento. En lugar de añadir estos patrones como una consideración posterior, podemos incorporarlos directamente en el diagrama de secuencia. Esto garantiza que el equipo de diseño entienda cómo interactúan estos patrones con el resto del sistema.
Patrones comunes en el flujo
- Mecanismos de reintento:Muestre un bucle donde un mensaje se reenvía tras un fallo.
- Tiempo de espera:Indique una línea vertical punteada donde el mensaje deja de esperar.
- Alternativas:Muestre una ruta alternativa que se sigue cuando falla el servicio principal.
- Interruptores de circuito: Representa un estado en el que el sistema deja de enviar solicitudes a un servicio que falla.
Al modelar estos patrones, la claridad es fundamental. Debemos usar notaciones distintas para el fallo y la recuperación. Por ejemplo, una flecha rota puede indicar un mensaje fallido. Una flecha punteada puede indicar un reintento. Este lenguaje visual permite a los interesados comprender rápidamente la estrategia de manejo de fallos.
| Patrón | Representación en diagrama | Beneficio |
|---|---|---|
| Reintento | Fragmento de bucle con condición | Evita que los fallos transitorios causen errores |
| Interruptor de circuito | Mensaje condicional (estado abierto) | Evita que los fallos en cadena afecten a servicios secundarios |
| Respuesta alternativa | Fragmento alternativo (Alt) | Proporciona una experiencia degradada pero funcional |
| Tiempo de espera agotado | Fragmento combinado con límite de tiempo | Evita que los recursos se mantengan indefinidamente |
Al visualizar estos patrones, pasamos de la teoría abstracta al diseño concreto. Los desarrolladores pueden ver exactamente dónde ocurre la lógica de reintento y qué desencadena la respuesta alternativa. Esto reduce la ambigüedad durante la implementación.
5. Manejo eficaz de tiempos de espera y reintentos ⏳
Las redes son poco confiables. Los servicios se caen. Los picos de latencia son comunes. Un sistema resiliente debe manejar estas realidades con elegancia. Los diagramas de secuencia son el mejor lugar para definir las reglas para tiempos de espera y reintentos. Sin estas definiciones, los desarrolladores hacen suposiciones que varían de una persona a otra.
Considere una integración con una API externa. Si la API devuelve un error 503 Servicio no disponible, ¿debería el sistema reintentar inmediatamente? ¿Debería esperar? ¿Cuántas veces? Estas preguntas deben responderse en la fase de diseño. El diagrama de secuencia proporciona el lienzo para estas decisiones.
Definición de la lógica de reintento
- Retraso exponencial: El tiempo de espera aumenta con cada intento de reintento.
- Máximo de reintentos: Un límite rígido sobre cuántas veces se reintenta una solicitud.
- Clasificación de errores: Distinguir entre errores transitorios (reintentables) y errores permanentes (no reintentar).
- Colas de mensajes fallidos: Moviendo los mensajes fallidos a un almacenamiento separado para su análisis.
Al documentar esto en un diagrama, debemos especificar las condiciones para cada rama. Por ejemplo, «Si la respuesta es 500, reintente hasta 3 veces con retroceso. Si la respuesta es 400, aborte». Este nivel de detalle asegura que el código coincida con la intención del diseño.
También es importante considerar el impacto de los reintentos en el sistema. Los reintentos excesivos pueden sobrecargar precisamente el servicio que ya está teniendo problemas. Esto se conoce como el problema de la manada tronadora. Los diagramas de secuencia ayudan a visualizar esta carga. Al mostrar múltiples solicitudes concurrentes que se reintentan, podemos ver el potencial de agotamiento de recursos.
6. Comunicación entre sistemas y límites 🌐
Los sistemas modernos son distribuidos. Cubren múltiples entornos, nubes o centros de datos. La comunicación entre estos límites introduce complejidad. Las particiones de red, los fallos de DNS y las reglas del cortafuegos pueden interrumpir todos el flujo. Los diagramas de secuencia ayudan a delimitar claramente estos límites.
Al dibujar un diagrama de secuencia para un sistema distribuido, debemos separar visualmente diferentes dominios. Esto se puede hacer utilizando marcos particionados o colores de fondo distintos. Esta separación destaca dónde existen los límites de confianza y dónde se requiere cifrado.
Seguridad y resiliencia
- Flujos de autenticación:Asegúrese de que los tokens se pasen de forma segura entre los servicios.
- Cifrado:Indique dónde se cifra los datos en tránsito.
- Límite de tasa:Muestre dónde se limitan las solicitudes para prevenir el abuso.
- Validación de entrada:Confirme que los datos se verifican antes de procesarlos.
Al incluir estos elementos de seguridad en el diagrama de secuencia, aseguramos que la resiliencia no se trate solo de disponibilidad, sino también de integridad y confidencialidad. Un sistema que está disponible pero comprometido no es resiliente.
7. Colaboración y estándares de documentación 🤝
Un diagrama de secuencia es una herramienta de comunicación. Crea un puente entre arquitectos, desarrolladores y testers. Para que sea efectivo, debe seguir estándares consistentes. Esto asegura que todos interpreten el diagrama de la misma manera.
Mejores prácticas para el mantenimiento
- Control de versiones:Trate los diagramas como código. Guárdelos en sistemas de control de versiones.
- Proceso de revisión:Incluya diagramas en las revisiones de código y en las reuniones de revisión de diseño.
- Documentos vivos:Actualice los diagramas cuando cambie el sistema. Los diagramas desactualizados son peligrosos.
- Validación automatizada:Utilice herramientas para verificar que la implementación coincida con el diagrama.
Cuando un diagrama se vuelve obsoleto, pierde su valor. Puede inducir a los desarrolladores a pensar que una característica funciona cuando no es así. Para prevenir esto, debemos integrar las actualizaciones de los diagramas en la canalización de despliegue. Si cambia el código, el diagrama también debe cambiar. Esto crea una cultura de precisión y confiabilidad.
8. Refinamiento iterativo y mantenimiento 🔄
El diseño del sistema nunca termina. A medida que aprendemos más sobre cómo se comporta el sistema, refinamos los diagramas. Este proceso iterativo es vital para la resiliencia a largo plazo. No podemos predecir cada modo de fallo, pero podemos mejorar nuestra comprensión con el tiempo.
Después de un incidente en producción, debemos revisar los diagramas de secuencia. ¿El diagrama reflejó lo que realmente sucedió? Si no, ¿por qué? Este análisis póstumo nos ayuda a mejorar nuestras habilidades de modelado. Nos ayuda a identificar lagunas en nuestra comprensión del sistema.
Bucle de Mejora Continua
- Observar:Monitorear el comportamiento del sistema en producción.
- Documentar:Actualizar los diagramas para reflejar el comportamiento observado.
- Simular:Utilizar la ingeniería de caos para probar los escenarios en el diagrama.
- Perfeccionar:Ajustar el diseño según los resultados de la simulación.
Al tratar el diagrama de secuencias como un artefacto vivo, garantizamos que siga siendo una representación fiel del sistema. Esto nos permite detectar problemas temprano. Nos permite planificar para el fracaso. Y en última instancia, nos permite construir sistemas que perduren.
Reflexiones Finales sobre el Diseño de Sistemas 🏁
Construir sistemas resilientes requiere disciplina. Requiere que pensemos en el fracaso antes de que ocurra. El análisis de diagramas de secuencias proporciona la estructura que necesitamos para hacer esto. Nos obliga a prestar atención a los detalles. Nos obliga a considerar los bordes.
Al utilizar estos diagramas de forma efectiva, podemos reducir el riesgo. Podemos mejorar la confiabilidad. Podemos crear software en el que los usuarios puedan confiar. Esto no se trata de magia ni atajos. Se trata de un análisis riguroso y una comunicación clara. Cuando obtenemos la secuencia correcta, el sistema sigue.

