











Проектирование программного обеспечения, способного выдерживать сбои, — это критическая ответственность для любой инженерной команды. Устойчивость — это не просто функция, а основа современных распределённых систем. Чтобы достичь этого, мы должны выйти за рамки статической архитектуры и изучить динамические взаимодействия между компонентами. Диаграммы последовательности предоставляют мощный инструмент для такого анализа. Составляя карту потока сообщений и данных, мы можем выявить уязвимые места до того, как они превратятся в инциденты в продакшене. В этом руководстве рассматривается, как использовать анализ диаграмм последовательности для создания надёжных, отказоустойчивых систем.
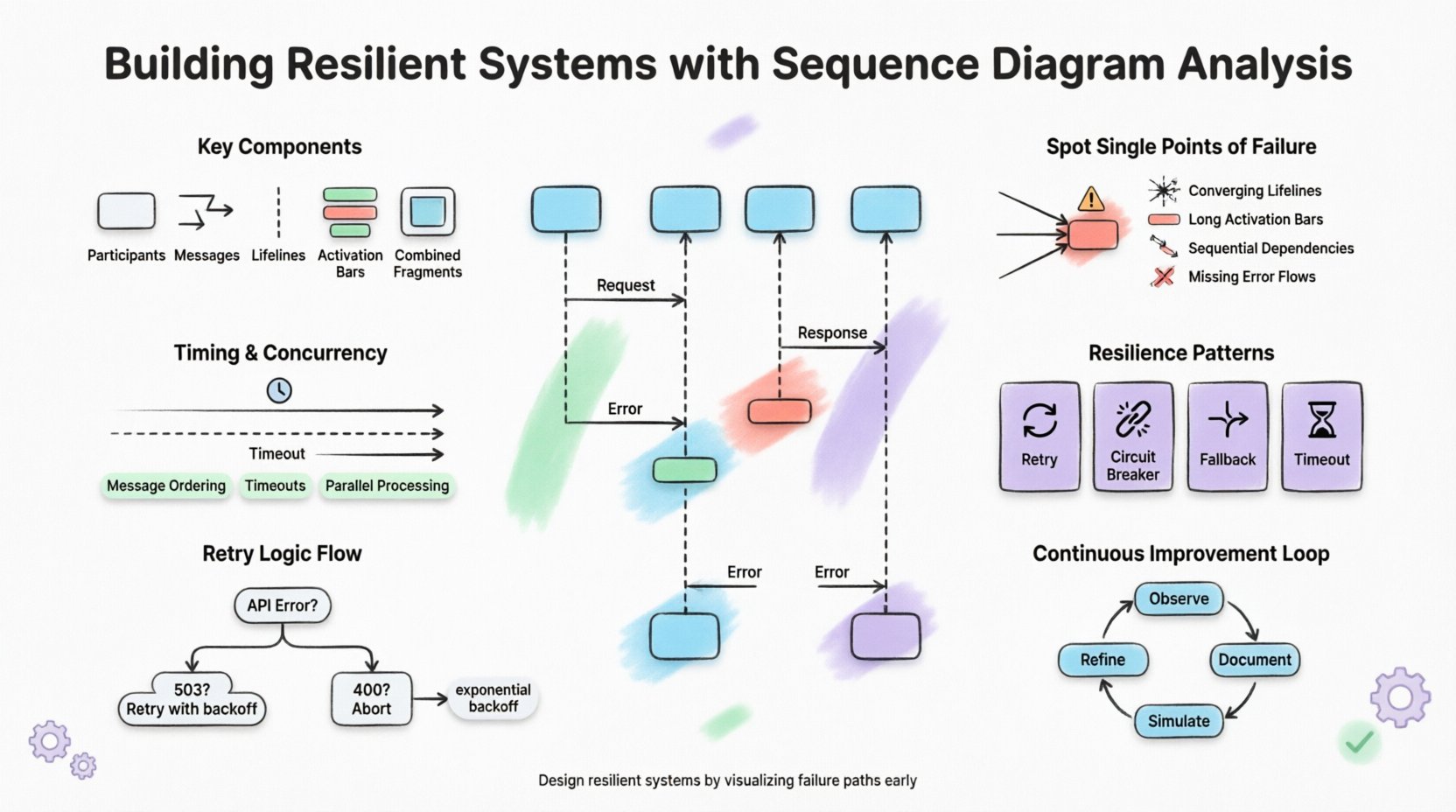
1. Основа диаграмм последовательности в архитектуре 🧩
Прежде чем углубляться в устойчивость, мы должны понять сам инструмент. Диаграмма последовательности — это визуальное представление взаимодействий между объектами или компонентами во времени. Она показывает порядок сообщений, участников и временные рамки событий. В контексте проектирования устойчивых систем эти диаграммы служат чертежом поведения системы при нагрузке.
При анализе системы мы не просто ищем «счастливые пути». Мы ищем грани. «Счастливый путь» — это сценарий, при котором всё работает идеально. «Несчастливый путь» — это ситуация, когда возникает сетевая задержка, сервисы зависают или данные повреждаются. Диаграммы последовательности позволяют визуализировать оба пути одновременно. Такое двойное представление необходимо для всестороннего проектирования системы.
Ключевые компоненты для моделирования
- Участники: Представляют службы, базы данных или внешние API, участвующие в процессе.
- Сообщения: Показывают поток запросов и ответов между участниками.
- Жизненные линии: Обозначают существование объекта в течение определённого времени.
- Активационные полосы: Показывают, когда объект выполняет действие.
- Совмещённые фрагменты: Позволяют изображать циклы, альтернативы и необязательные разделы.
Тщательно определяя эти элементы, мы создаём контракт поведения. Этот контракт становится основой для тестирования и проверки. Если реализация не соответствует диаграмме последовательности, значит, в проектировании есть пробел. Как правило, именно в таких пробелах возникают сбои.
2. Выявление точек отказа 🔍
Одной из основных целей анализа диаграмм последовательности является выявление точек отказа. Точка отказа — это компонент, сбой которого приводит к полному отказу всей системы. На диаграмме последовательности такие компоненты часто выглядят как критический путь, по которому каждое сообщение должно пройти через определённый узел.
Рассмотрим типичный процесс обработки заказов. Если каждый заказ должен пройти через определённый сервис проверки перед попаданием в платёжный шлюз, этот сервис становится узким местом. Если он выходит из строя, вся цепочка обработки заказов останавливается. Диаграммы последовательности сразу же делают эту зависимость очевидной.
Визуальные признаки риска
| Визуальный элемент | Последствия для устойчивости | Пример |
|---|---|---|
| Сходящиеся жизненные линии | Множество потоков зависят от одного компонента | Заказ, оплата и уведомление проходят через один сервис аутентификации |
| Длинные активационные полосы | Компонент занят в течение длительного времени | Блокирующий вызов во время синхронного запроса |
| Последовательные зависимости | Сбой на этапе A блокирует этап B | Этап 1 должен завершиться до начала этапа 2 |
| Отсутствуют потоки обработки ошибок | Нет обработки сценариев сбоев | Показаны только сообщения об успешном завершении |
Чтобы снизить эти риски, необходимо пересмотреть последовательность. Это может включать введение избыточности или изменение потока на асинхронный. Цель состоит в том, чтобы обеспечить, что сбой одного компонента не приведет к полному выходу системы из строя.
3. Анализ параллелизма и ограничений по времени ⏱️
Устойчивость также зависит от времени. Системы часто выходят из строя не из-за логических ошибок, а из-за проблем со временем. Гонки условий, таймауты и сценарии взаимоблокировки трудно обнаружить в коде, но они очевидны на диаграммах последовательности. Когда несколько компонентов действуют одновременно, порядок операций имеет значение.
Например, представьте, что пользователь обновляет свой профиль одновременно с запросом на сессию входа. Если диаграмма последовательности не учитывает временные характеристики этих одновременных запросов, система может обработать устаревшую версию данных. Это приводит к несогласованности данных — распространённой причине проблем с устойчивостью.
Методы анализа временных характеристик
- Порядок сообщений:Убедитесь, что зависимые сообщения отправляются в правильной последовательности.
- Длительность таймаутов:Укажите, как долго компонент ждет ответа перед отменой операции.
- Параллельная обработка:Используйте комбинированные фрагменты для отображения независимых операций, выполняющихся одновременно.
- Синхронизация состояния:Убедитесь, что обновления состояния происходят до выполнения зависимых действий.
Добавляя в диаграмму ограничения по времени, мы заставляем команду учитывать задержки. Это критически важно для систем, зависящих от данных в реальном времени. Если сервис ожидает ответ в течение 500 миллисекунд, диаграмма последовательности должна отражать это ожидание. Если нижестоящий сервис не может удовлетворить этому требованию, диаграмма выявляет потенциальный режим сбоя.
4. Встраивание паттернов устойчивости непосредственно 🔄
Паттерны устойчивости — это проверенные решения для типичных архитектурных проблем. К ним относятся прерыватели цепей, перегородки и логика повторных попыток. Вместо того чтобы добавлять эти паттерны как после мысль, мы можем встроить их непосредственно в диаграмму последовательности. Это гарантирует, что команда разработчиков понимает, как эти паттерны взаимодействуют с остальной частью системы.
Распространённые паттерны в потоке
- Механизмы повторных попыток:Покажите цикл, в котором сообщение повторно отправляется после сбоя.
- Таймауты:Укажите вертикальную штриховую линию, где сообщение прекращает ожидание.
- Резервные варианты:Покажите альтернативный путь, который используется при сбое основного сервиса.
- Прерыватели цепей: Представляет состояние, при котором система прекращает отправку запросов к неисправному сервису.
При моделировании этих паттернов важна ясность. Мы должны использовать различные обозначения для сбоев и восстановления. Например, разорванный стрелка может указывать на неудачное сообщение. Штриховая стрелка может указывать на повторную попытку. Этот визуальный язык позволяет заинтересованным сторонам быстро понять стратегию обработки сбоев.
| Паттерн | Представление диаграммы | Выгода |
|---|---|---|
| Повторная попытка | Фрагмент цикла с условием | Предотвращает возникновение ошибок из-за временных сбоев |
| Прерыватель цепи | Условное сообщение (состояние открытия) | Предотвращает цепную реакцию сбоев в нижестоящих сервисах |
| Резервная система | Альтернативный фрагмент (Alt) | Обеспечивает ухудшенный, но рабочий опыт |
| Тайм-аут | Совмещенный фрагмент с ограничением времени | Предотвращает бесконечное удержание ресурсов |
Визуализируя эти паттерны, мы переходим от абстрактной теории к конкретному проектированию. Разработчики могут точно увидеть, где происходит логика повторной попытки, и что запускает резервную систему. Это снижает неоднозначность при реализации.
5. Эффективное управление тайм-аутами и повторными попытками ⏳
Сети ненадежны. Сервисы выходят из строя. Появляются пиковые задержки. Устойчивая система должна гибко справляться с этими реалиями. Диаграммы последовательности — лучшее место для определения правил тайм-аутов и повторных попыток. Без этих определений разработчики делают предположения, которые различаются у разных людей.
Рассмотрим интеграцию с внешним API. Если API возвращает ошибку 503 «Сервис недоступен», следует ли системе немедленно повторить попытку? Должна ли она ждать? Сколько раз? Эти вопросы должны быть решены на этапе проектирования. Диаграмма последовательности предоставляет основу для этих решений.
Определение логики повторной попытки
- Экспоненциальная задержка: Время ожидания увеличивается с каждой попыткой повтора.
- Максимальное количество повторов: Жесткое ограничение на количество повторных попыток запроса.
- Классификация ошибок: Различение временных ошибок (подлежащих повторной попытке) и постоянных ошибок (не подлежащих повторной попытке).
- Очереди сообщений с ошибками: Перемещение неудачных сообщений в отдельное хранилище для анализа.
При документировании этого на диаграмме мы должны указать условия для каждого ветвления. Например: «Если ответ — 500, повторить до 3 раз с задержкой. Если ответ — 400, прервать». Такая степень детализации гарантирует, что код соответствует замыслу проектирования.
Важно также учитывать влияние повторных попыток на систему. Чрезмерные повторные попытки могут перегрузить именно тот сервис, который и так испытывает трудности. Это известно как проблема «глухого стада». Диаграммы последовательности помогают визуализировать эту нагрузку. Показывая несколько одновременных запросов, повторяющих попытки, мы можем увидеть потенциальную угрозу исчерпания ресурсов.
6. Коммуникация между системами и границы 🌐
Современные системы распределённые. Они охватывают несколько сред, облаков или центров обработки данных. Коммуникация между этими границами вносит сложность. Разрывы сети, сбои DNS и правила брандмауэра могут нарушить поток. Диаграммы последовательности помогают чётко отобразить эти границы.
При создании диаграммы последовательности для распределённой системы мы должны визуально разделять различные домены. Это можно сделать с помощью разделённых рамок или различных цветов фона. Такое разделение подчёркивает, где находятся границы доверия и где требуется шифрование.
Безопасность и отказоустойчивость
- Потоки аутентификации: Убедитесь, что токены передаются безопасно между службами.
- Шифрование: Укажите, где данные шифруются при передаче.
- Ограничение скорости: Покажите, где запросы ограничиваются, чтобы предотвратить злоупотребление.
- Проверка входных данных: Убедитесь, что данные проверяются перед обработкой.
Включая эти элементы безопасности на диаграмме последовательности, мы гарантируем, что отказоустойчивость — это не только доступность, но и целостность и конфиденциальность. Система, доступная, но скомпрометированная, не является отказоустойчивой.
7. Сотрудничество и стандарты документирования 🤝
Диаграмма последовательности — это инструмент коммуникации. Она устраняет разрыв между архитекторами, разработчиками и тестировщиками. Чтобы она была эффективной, она должна следовать единым стандартам. Это гарантирует, что все интерпретируют диаграмму одинаково.
Лучшие практики обслуживания
- Контроль версий: Рассматривайте диаграммы как код. Храните их в системах контроля версий.
- Процесс проверки: Включайте диаграммы в процессы проверки кода и обсуждения архитектуры.
- Живые документы: Обновляйте диаграммы при изменении системы. Устаревшие диаграммы опасны.
- Автоматическая проверка: Используйте инструменты для проверки соответствия реализации диаграмме.
Когда диаграмма устаревает, она теряет свою ценность. Она может ввести разработчиков в заблуждение, заставив их думать, что функция работает, хотя на самом деле она не работает. Чтобы избежать этого, мы должны интегрировать обновления диаграмм в процесс развертывания. Если код меняется, диаграмма должна меняться. Это создаёт культуру точности и надёжности.
8. Итеративное уточнение и обслуживание 🔄
Проектирование системы никогда не заканчивается. По мере того как мы лучше понимаем поведение системы, мы уточняем диаграммы. Этот итеративный процесс жизненно важен для долгосрочной отказоустойчивости. Мы не можем предсказать каждый возможный сбой, но можем постепенно улучшать своё понимание.
После инцидента в продакшене мы должны проанализировать диаграммы последовательности. Отражала ли диаграмма то, что действительно произошло? Если нет, почему? Такой анализ после инцидента помогает нам улучшить навыки моделирования. Он помогает выявить пробелы в нашем понимании системы.
Цикл непрерывного улучшения
- Наблюдайте: Контролируйте поведение системы в рабочей среде.
- Документируйте: Обновляйте диаграммы, чтобы отразить наблюдаемое поведение.
- Симулируйте: Используйте инженерию хаоса для проверки сценариев на диаграмме.
- Уточняйте: Корректируйте архитектуру на основе результатов симуляции.
Рассматривая диаграмму последовательности как живой артефакт, мы гарантируем, что она остается точным отражением системы. Это позволяет нам выявлять проблемы на ранних этапах. Это позволяет нам планировать отказы. И в конечном итоге, это позволяет нам создавать системы, способные выдерживать испытания временем.
Заключительные мысли о проектировании систем 🏁
Создание устойчивых систем требует дисциплины. Требуется думать о сбоях до их наступления. Анализ диаграмм последовательностей предоставляет структуру, необходимую для этого. Он заставляет нас обращать внимание на детали. Он заставляет нас учитывать крайние случаи.
Эффективно используя эти диаграммы, мы можем снизить риски. Мы можем повысить надежность. Мы можем создавать программное обеспечение, которому пользователи могут доверять. Речь не идет о магии или упрощениях. Речь идет о строгом анализе и четкой коммуникации. Когда мы правильно определяем последовательность, система следует за ней.

